

Best Use Cases for the RTX 3060 on SimplePod — From Students to Devs Starting Out
The RTX 3060 is the perfect starting GPU on SimplePod — ideal for students, hobbyists, and developers training small models, testing inference, and building early AI prototypes without overspending.

How SimplePod’s Preconfigured Templates (Ollama, Jupyter, etc.) Perform on Different GPUs (3060 / 4090 / A4000)
See how SimplePod’s pre-configured templates — Ollama, Jupyter, and more — perform across different GPUs. Compare startup times, inference speed, and memory use for the 3060, A4000, and 4090 to find the right fit for your workflow.

Scaling with Multiple RTX 4090s on SimplePod: What to Expect & How to Manage
Scaling with multiple RTX 4090s on SimplePod unlocks massive training power. Learn how data parallelism, network bandwidth, and storage management shape performance — and how to orchestrate efficient multi-GPU workflows in the cloud.
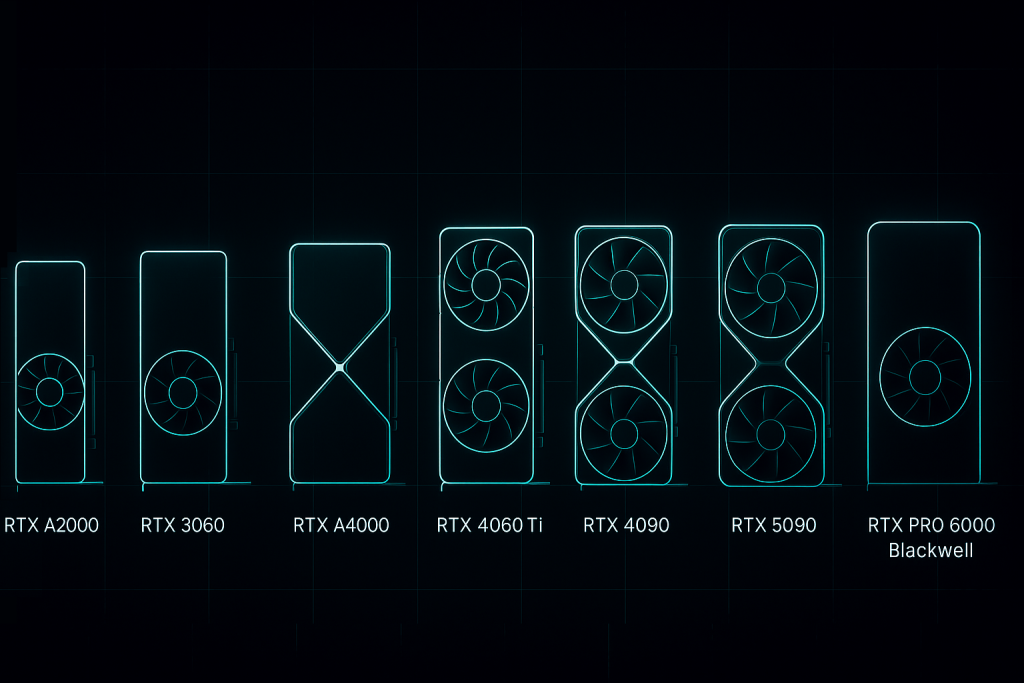
SimplePod GPU Cards Comparison: Specs, VRAM, Bandwidth, and What That Means for AI/ML Users
Compare all GPUs available on SimplePod — from the entry-level RTX 3060 to the powerhouse PRO 6000 Blackwell. Learn what VRAM, bandwidth, and CUDA cores really mean for your AI and ML workloads.
Monitoring Your GPU Instances
Introduction When training AI models or rendering simulations, nothing is more frustrating than slowdowns, out-of-memory errors, or mysterious...

AI Doesn’t Have to Break Your Startup’s Bank Account: The Cloud GPU Solution
AI doesn’t have to drain your budget. With cloud GPUs, startups can rent top-tier compute power by the hour, scale as needed, and focus on building products — not buying hardware.
Zero Setup, Maximum Productivity: Harnessing SimplePod’s Pre-Configured AI Environments
Setting up AI environments shouldn’t feel like a battle with CUDA drivers and dependency hell. SimplePod’s pre-configured GPU environments let you skip the setup entirely and get straight to building, training, and experimenting. Whether you’re a student, startup, or researcher, launch in minutes and focus on results — not roadblocks.

How to Start with Ollama on SimplePod.ai: Run Local LLMs with Rented GPUs
Introduction Running large language models (LLMs) locally gives developers the freedom to experiment, customize, and maintain privacy. Ollama...

Training Large Language Models on Simplepod
Let’s face it – training large language models (LLMs) is a massive undertaking. The computational demands are staggering,...

Here’s How to Instantly Boost Your Jupyter Productivity
What’s Slowing You Down in Jupyter – And How to Fix It In the dynamic realms of data...